Executive Overview
Truelty offers two powerful tools for advanced users to fine-tune the high-level processing rules and maintain the Semantic Categories. With our detailed documentation, including sample code and common use cases, you can easily customize Truelty to meet your specific business requirements.
Our stored procedures protect against incorrect values being set and provide the ability to roll back to default settings for individual items or everything. This ensures the highest level of accuracy and performance for your identity resolution process.
In addition, we offer a deep dive into how Truelty utilizes Semantic Categories to drive the identity resolution process. This comprehensive understanding will allow advanced users to further optimize Truelty for real-world scenarios.
- Advanced Processing Configuration for Truelty
- alter_config
alter_config( <action> string)alter_config( <config_key> string, <config_value> string)
- alter_config
- Advanced Semantic Categories Configuration for Truelty
- scoring_config_view
(<action> string) - scoring_config
($$ <key> : <value> comma separated list $$)
- scoring_config_view
Advanced Processing Configuration for Truelty
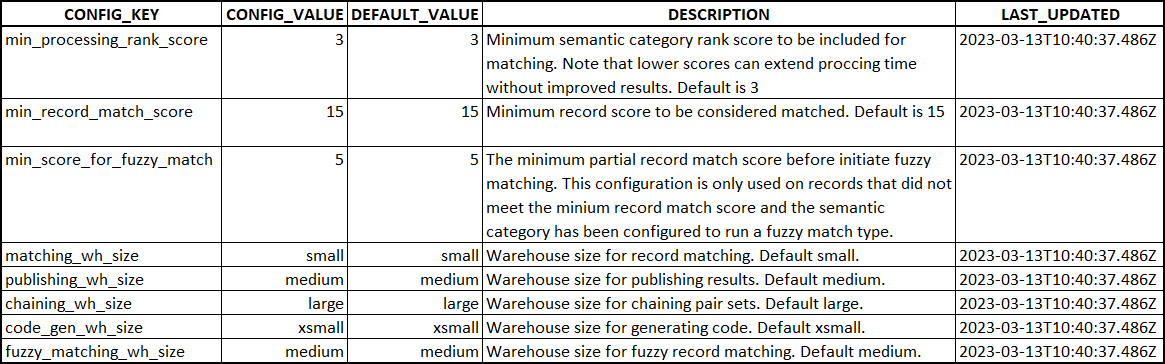
Truelty offers advanced users the flexibility to fine-tune the high-level processing controls of the system with the ALTER_CONFIG stored procedure. This powerful tool enables you to customize thresholds for semantic categories processing, minimum record matching, fuzzy matching thresholds, and warehouse size for various types of Truelty processes.
These settings are managed using a stored procedure called **alter_config. Allowing the Truelty administrator to change the settings in the config_value column in the TRUELTY_CONFIG table while ensuring that the configuration changes meet the minimum requirements.
By using these configurations, Truelty administrators can gain greater control and customization over the identity resolution process, leading to improved performance and accuracy. You can tailor Truelty to fit the specific data requirements and processing needs of your organization.
Actions & Configurations that can be made using **alter_config SP:
- View the current configuration settings
- Reset Truelty configurations back to default
- Adjusting Truelty scoring thresholds:
- Minimum semantic category rank score to include in the processing
- Minimum record match score to be considered as a matched record
- Minimum record-matched score to be considered for a fuzzy matching second pass
- Configuring Snowflake warehouse size to be used for the various steps in the matching process.
Below is a screenshot of the TRUELTY_CONFIG table that is managed via the alter_config stored procedure.
Stored Procedure Schema Path, Name, Parameters, & Data Type
truelty.data_store.alter_config(<action> string)
truelty.data_store.alter_config(<config_key> string, <config_value> string)
Code examples using the **alter_config Stored Procedure
/*******************************************************************
Advanced Configuration for Truelty
********************************************************************/
----| Setting the Snowflake Context for Truelty |----
Use role truelty_svc;
Use Schema truelty.data_store;
Use Warehouse truelty;
----| Viewing & Resetting Truelty Configuration |----
call truelty.data_store.alter_config('list');
call truelty.data_store.alter_config('reset');
----| Adjusting Truelty min matching_score & rank_score |----
call truelty.data_store.alter_config('min_record_match_score',13);
call truelty.data_store.alter_config('min_processing_rank_score',3);
call truelty.data_store.alter_config('min_score_for_fuzzy_match',5);
----| Adjusting Truelty Base Warehouse Sizes |----
call truelty.data_store.alter_config('matching_wh_size','xsmall');
call truelty.data_store.alter_config('publishing_wh_size','small');
call truelty.data_store.alter_config('chaining_wh_size','medium');
call truelty.data_store.alter_config('code_gen_wh_size','xsmall');
call truelty.data_store.alter_config('fuzzy_matching_wh_size','small');
----| Resetting Truelty Config Back to Default |----
call truelty.data_store.alter_config('reset','all');
call truelty.data_store.alter_config('reset','min_processing_rank_score');
call truelty.data_store.alter_config('reset', 'matching_wh_size');
Description of each Config_Key and valid Config_Value(s)
-
**
min_processing_rank_score:- The minimum rank score required for a semantic category to be included in the matching process. Lower scores can increase processing time without improving results.
- The default value is 3.
- It must be an integer value >= 1 and <= highest Rank Score assigned.
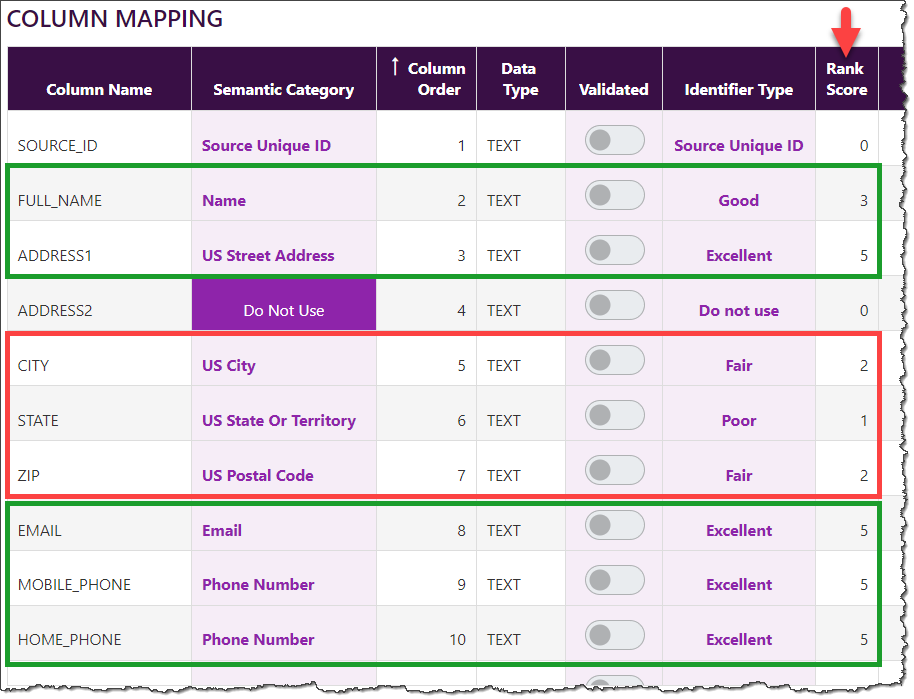
- In the screenshot below, let’s assume the
min_processing_rank_scoreis set to a value of 3. The columns mapped to Semantic Categories where the Rank Score >= 3 will be used in the matching processes. Ranking Scores less than 3 will be excluded.
-
min_record_match_score:- The minimum record score required for a record to be considered a match.
- The default value is 15.
- After all the Semantic Catigores are processed at the pair level, a sum of the matched rank scores by matched pair in the record is derived.
- If the record total is >= to the
min_record_match_score,then the record is considered matched. - If the summary of the record is >0 but less than
min_record_match_score,this is considered a partially matched record and may be considered for Fuzzy Matching.
- If the record total is >= to the
-
min_score_for_fuzzy_match:- The minimum partial record match score required to initiate fuzzy matching for semantic categories configured to use fuzzy matching. This setting is only used for records that did not meet the minimum record match score.
-
matching_wh_size:- The warehouse size used for record matching. The default size is small.
-
publishing_wh_size:- The warehouse size used for publishing results. The default size is medium.
-
chaining_wh_size:- The warehouse size used for chaining pair sets. The default size is large.
-
code_gen_wh_size:- The warehouse size used for generating code. The default size is xsmall.
-
fuzzy_matching_wh_size:- The warehouse size used for fuzzy record matching. The default size is medium.
Semantic Categories
Semantic categories are used in Truelty to group or categorize attributes based on their meaning or purpose. A semantic category is a classification system that groups similar data elements or entities based on their meaning or semantics. In data identification and deduplication or identity resolution, the semantic category can be used to improve the accuracy of matching records by analyzing the underlying semantics of the data attributes. Each category has specific elements that define its characteristics and how it will be used in identity resolution.
Semantic Category definitions are maintained in the CLASS_ID_TYPE_XREF table, and the Truelty administrator can make changes using these two stored procedures:
- scoring_config_view(<action>)
- Used for listing or resetting the current values in the CLASS_ID_TYPE_XREF table
- scoring_config($$<Key:Value> delimited list$$)
- Used for performing controlled actions on the CLASS_ID_TYPE_XREF table:
- Add
- Update
- Delete
- Reset
- Used for performing controlled actions on the CLASS_ID_TYPE_XREF table:
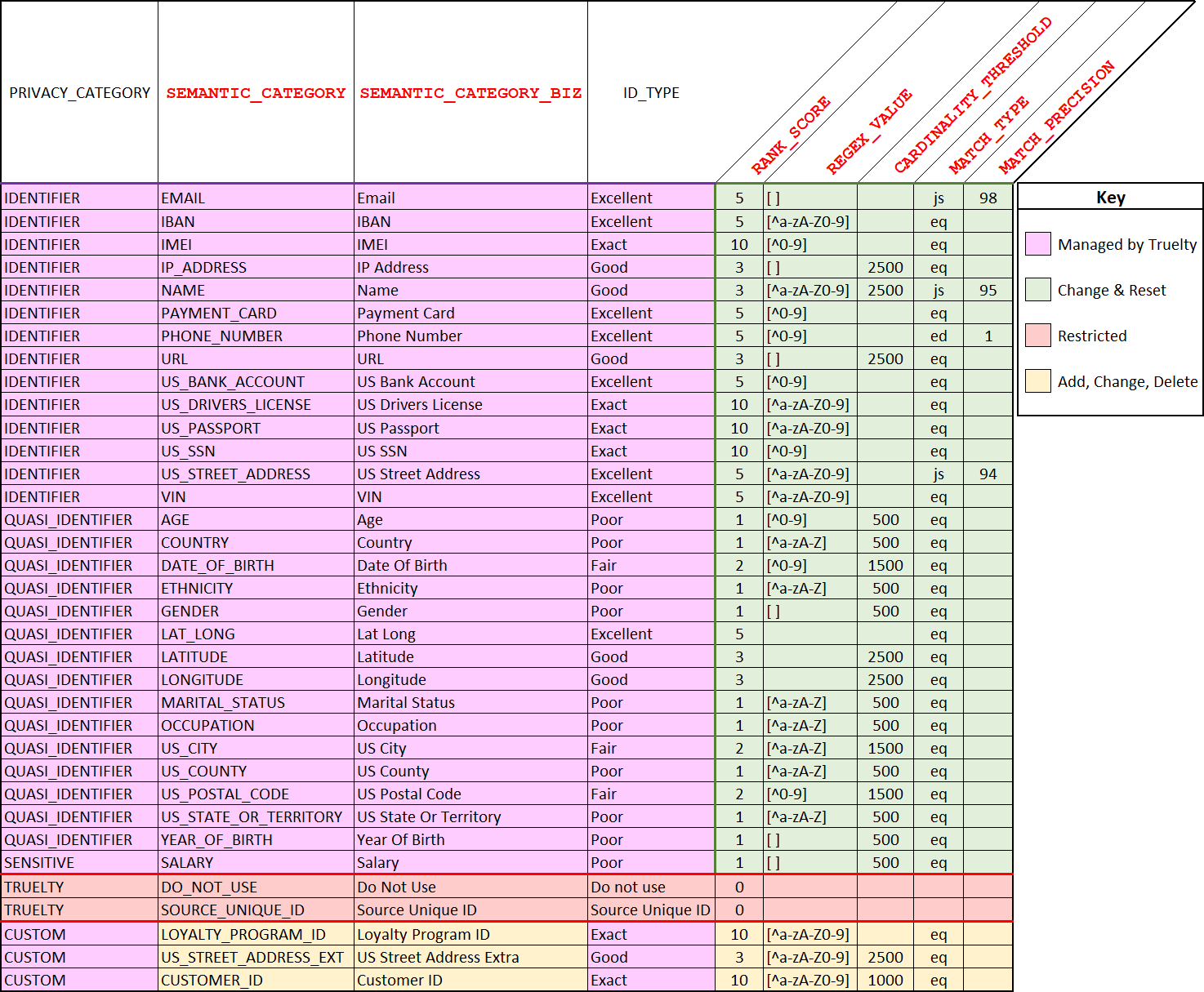
There are parts of the Semantic Category control table that can be added, changed, deleted, or reset. The scoring_config(<string>) stored procedure ensures that these changes follow the rules to maintain stability.
The view above of the Semantic Category Control Table is broken into the sections and colors to indicate what values are exposed to the Truelty administrator to change, add, delete, or reset.
The column titles in red are also the key names when using the scoring_config(<string>) stored procedure for making changes.
Description of the key columns in the Semantic Category Definitions Table:
- SEMANTIC_CATEGORY: This is the name of the Semantic Category as used by Truelty.
- SEMANTIC_CATEGORY_BIZ: This is the business-friendly version of the Semantic Category and is what is used in the UI for Mapping table columns to semantic categories
- ID_TYPE: Specifies the matching quality or strength of the semantic category.
- RANK_SCORE: Assigns a numerical score to the category based on its importance or relevance in identifying a match. A higher score indicates the quality of matching,
- REGEX_VALUE: Defines a regular expression pattern used to exclude charters from the data to make it cleaner prior to matching.
- CARDINALITY_THRESHOLD: specifies the maximum number of duplicate values in a specific semantic category’s data before it is removed from the matching process. This helps exclude low-quality matches and improve accuracy. The threshold can be adjusted based on business rules, allowing for more customized and targeted matching. It is an important tool in identity resolution, removing low-quality matches and improving accuracy.
- A common name like John Smith may lose its value for matching when there are many occurrences of it in the data. To address this, organizations can set a CARDINALITY_THRESHOLD specifying how many occurrences of a data type they will allow before removing it from the matching process. This helps improve the accuracy of identifying duplicate records and ensures that only high-quality matches are included.
- MATCH_TYPE: Defines the type of matching algorithm used for the category. There are currently 3 types. EQ - Equality, ED - Edit Distance, & JS: Jaro-Winkler similarity.
- Note: Edit Distance and Jaro-Winkler Similarity are fuzzy matching methods that are used as a second pass of matching after the equality pass has been performed.
- MATCH_PRECISION: Specifies the level of precision or accuracy required for fuzzy matching methods.
Truelty comes with a set of default semantic categories that can be used for identity resolution, including identifiers, quasi-identifiers, sensitive data, and special categories that should not be used for matching. These categories can be customized, or new categories can be added to fit the specific needs of different use cases.
Code Examples and Common Use Cases for scoring_config_view & scoring_config SP
Advanced Access to Truelty Semantic Category Scoring
********************************************************************/
----| Set Truelty Snowflake Contex |----
use role truelty_svc;
use schema truelty.data_store;
use warehouse truelty;
----| Viewing & Resetting Truelty Semantic Category Scoring |----
call scoring_config_view('list');
call scoring_config_view('reset');
----| Adding a New Semantic Category |----
call scoring_config($$
'action': 'add',
'semantic_category': 'CUSTOMER_ID',
'semantic_category_biz': 'Customer ID',
'rank_score': 10,
'regex_value': '[^a-zA-Z0-9]',
'cardinality_threshold': 1000,
'match_type': 'js',
'match_precision': 95
$$);
----| Changing/Updating a Semantic Category |----
call scoring_config($$
'action': 'update',
'semantic_category': 'CUSTOMER_ID',
'semantic_category_biz': 'Cust ID',
'rank_score': 5,
'regex_value': '[^0-9]',
'cardinality_threshold': 500,
'match_type': 'ed',
'match_precision': 1
$$);
----| Changing/Updating one specific Semantic Category Value |----
call scoring_config($$
'action': 'update',
'semantic_category': 'CUSTOMER_ID',
'rank_score': 10,
$$);
----| Common Semantic Category Updates for Fuzzy Matching |----
call scoring_config($$
'action': 'update',
'semantic_category': 'NAME',
'match_type': 'js',
'match_precision': 95
$$);
call scoring_config($$
'action': 'update',
'semantic_category': 'EMAIL',
'match_type': 'js',
'match_precision': 95
$$);
call scoring_config($$
'action': 'update',
'semantic_category': 'PHONE_NUMBER',
'match_type': 'ed',
'match_precision': 1
$$);
call scoring_config($$
'action': 'update',
'semantic_category': 'US_STREET_ADDRESS',
'match_type': 'js',
'match_precision': 90
$$);
----| Resetting one specific Semantic Category Back to Default |----
call scoring_config($$
'action': 'reset',
'semantic_category':'PHONE_NUMBER'
$$);
----| Resetting ALL the Semantic Category Back to Default |----
call scoring_config($$
'action': 'reset',
'semantic_category': 'ALL'
$$);
----| Deleting a Semantic Category from the CUSTOM Group |----
call scoring_config($$
'action': 'delete',
'Semantic_category': 'CUSTOMER_ID'
$$);
scoring_config : Detailed Definition of Actions, Key/Value Parameters
Parameters
semantic_category
- This parameter represents the name of the semantic category to be validated.
- It is a **required **parameter.
- The value needs to be a string and should represent a valid semantic category name.
- The name must not contain any spaces, but underscores can be used.
- The name must meet the same requirements as naming a snowflake table.
- The following actions can be performed on this parameter:
- Add
- Update
- Delete
- Reset
semantic_category_biz
- This parameter represents the business-friendly version of the semantic category to be validated.
- This is the value that will be shown in the UI when mapping columns to Semantic Categories
- It is a **required **parameter when using the **add **action.
- The value is a string and should represent a valid semantic category business version name.
- It can have mixed case as well as spaces.
- The following actions can be performed on this parameter:
- Add
- Update
rank_score
- This parameter represents the rank score or the ranking value of the semantic category as to how well it can be used for identity resolution.
- Below is the default ranking base on the identifiable quality of the semantic category.
- Exact - 10
- Excellent - 5
- Good - 3
- Fair - 2
- Poor - 1
- Below is the default ranking base on the identifiable quality of the semantic category.
- It is a **required **parameter for the **add **action.
- The value must be an integer and be greater than or equal to 1.
- The following actions can be performed on this parameter:
- Add
- Update
regex_value
- This parameter represents the regular expression pattern of what to exclude from the data before matching.
- Here are some common patterns used
- The use of the “^” is like saying ‘NOT’ or ‘Except’
- Number values only: [^0-9]
- Alpha text charters only: [^a-zA-Z]
- Alpha-Numeric text only: [^a-zA-Z0-9]
- If you want specific charters excluded, add those charters in the brackets. For example, if you wanted to have the charters “$#@&” removed from the data before matching, you would put [$#@&]
- It is a **required **parameter for the **add **action.
- The value should be a valid regular expression pattern.
- The following actions can be performed on this parameter:
- Add
- Update
cardinality_threshold
- This parameter represents the cardinality threshold to be validated.
- It is an optional parameter.
- The value must be an integer and be greater than or equal to 2.
- The value specifies the maximum number of duplicate values in a specific semantic category’s data before it is removed from the matching process. This helps exclude low-quality matches and improve accuracy. Adjusting the threshold value allows for more customized and targeted matching.
- It is an important adjustable value in identity resolution for removing low-quality matches and improving accuracy.
- Example: A common name like John Smith may lose its value for matching when there are many occurrences of it in the data. To address this, the CARDINALITY_THRESHOLD value specifies how many occurrences of the value like ‘John Smith’ in the Name semantic category will be allowed before removing it from the matching process. This helps improve the accuracy of identifying duplicate records and ensures that only high-quality matches are included.
- The following actions can be performed on this parameter:
- Add
- Update
match_type
- This parameter represents the type of match to be validated.
- It is an optional parameter; however, when left blank during add, the value of “eq” will be used as that is the primary matching method used.
- The value should be one of the following:
- eq - (for equality),
- js - (for Jaro-Winkler),
- ed - (for edit distance).
- The following actions can be performed on this parameter:
- Add
- Update
match_precision
- This parameter represents the precision of the match to be validated.
- It is an optional parameter when adding if the value “eq” was used for the match_type. However, if ‘js’ or ‘ed’ were used, then the match_precision parameter is required.
- The value must be an integer and be greater than or equal to 1.
- Recommended ranges to be used by Matching Type:
- EQ: None
- JS: 90 to 99
- ED: 1 to 3
- Recommended ranges to be used by Matching Type:
- The following actions can be performed on this parameter:
- Add
- Update
Validation Rules
When using the scoring_config() stored procedure, the procedure response indicates if the action was successful or there was an issue. If there was an issue, a detailed message(s) will indicate what caused the issue and how to fix it. Most of the issues and resolutions are based on the validation rules listed below by parameter key/value and the action that was to be performed.
semantic_category
- If the action is “add”, the semantic category cannot already be assigned.
- If the action is “update”, the semantic category should exist and be updatable.
- If the action is “reset”, the semantic category should not be protected from resetting. If the parameter value is “all”, all semantic categories that can be reset will be reset.
- If the action is “delete”, the semantic category should be a custom category that can be deleted.
semantic_category_biz
- If the action is “add”, the semantic category business version cannot already be assigned.
- If the action is “update”, the semantic category business version should exist and be updatable.
rank_score
- If the action is “add”, the rank score should be an integer greater than or equal to 1, and should have a valid ID type.
- If the action is “update”, the rank score should be an integer greater than or equal to 1, and should have a valid ID type.
regex_value
- If the regular expression pattern is provided, it should be a valid regular expression pattern used for excluding charters.
cardinality_threshold
- If provided, the cardinality threshold should be an integer greater than or equal to 2. If the rank score is less than 5, the cardinality threshold should be between 500 and 2500.
match_type
- Required field
- Allowed values: EQ, ED, JS
- EQ: Equality match type; an exact match is required
- ED: Edit distance match type, which allows for a specified amount of distance between elements.
- Computes the Levenshtein distance between strings. It is the number of single-character insertions, deletions, or substitutions needed to convert one string to another.
- JS: Jaro-Winkler similarity match type, allows for the similarity between elements.
- Matching ranges are between 0 and 100, where 0 indicates no similarity and 100 indicates an exact match
match_precision
- It is an optional parameter when adding if the value “eq” was used for the match_type. However, if ‘js’ or ‘ed’ were used, then the match_precision parameter is required.
- The value should be an integer and should be greater than or equal to 1.
- Recommended ranges to be used by Matching Type:
- EQ: None
- JS: 90 to 99
- ED: 1 to 3
Actions
Actions are used to create, update, or delete semantic categories. The available options for actions are:
- add: adds a new semantic category
- update: updates an existing semantic category
- delete: deletes an existing semantic category
- list: provides a list of the semantic categories
- reset: resets the base semantic categories to their default values
Each of these actions requires specific parameters, which we will cover in detail in the following sections.
Add Action
The add action is used to create a new semantic category.
The following parameters are required:
semantic_category: the name of the semantic category for automation purposes.- It must be in upper case, and with no use of spaces.
semantic_category_biz: the user-friendly version of the semantic category name.- Here you can use spaces and mixed cases.
rank_score: this is the ranking value of the semantic category as to how well it can be used for identity resolution.- Below is the default ranking base on the identifiable quality of the semantic category.
- Exact - 10
- Excellent - 5
- Good - 3
- Fair - 2
- Poor - 1
- Below is the default ranking base on the identifiable quality of the semantic category.
The following parameters are optional:
regex_value: charters to be excluded using a regex exclusion pattern.cardinality_threshold: maximum number of repeated values in the semantic category before it is removed prior to matchingmatch_type: the match type for the semantic category, a value of ‘eq’ will be added by defaultmatch_precision: the details for match_type when JS or ED are used
Update Action
The update action is used to update an existing semantic category.
The following parameters are required:
semantic_category: the name of the semantic category to be updated
The following parameters are optional:
semantic_category_biz: the user-friendly version of the semantic category name.- Here you can use spaces and mixed cases.
rank_score: this is the ranking value of the semantic category as to how well it can be used for identity resolution.- Below is the default ranking base on the identifiable quality of the semantic category.
- Exact - 10
- Excellent - 5
- Good - 3
- Fair - 2
- Poor - 1
- Below is the default ranking base on the identifiable quality of the semantic category.
regex_value: charters to be excluded using a regex exclusion pattern.cardinality_threshold: maximum number of repeated values in the semantic category before it is removed prior to matchingmatch_type: the match type for the semantic category, a value of ‘eq’ will be added by defaultmatch_precision: the details for match_type when JS or ED are used
Delete Action
The delete action is used to delete an existing semantic category.
The following parameter is required:
semantic_category: the name of the semantic category to be deleted
List Action
The list action is used to list the current semantic categories.
Reset Action
The reset action is used to reset the core semantic categories back to their default values. Custom semantic categories do not support default values.
The following parameter is required:
semantic_category: the name of the semantic category to be reset or the value ALL.- If the semantic_category name is provided, then only that semantic category will be reset.
- If the value of ALL is used, all core semantic categories will be reset.
Deep Dive on Semantic Categories
Executive Overview
Truelty is an identity resolution tool built on the Snowflake engine that utilizes semantic categories to group similar data elements or entities together based on their semantics. Semantic categories are assigned a rank score based on their matching ability, which prioritizes matching and improves the accuracy of identifying duplicate records.
Truelty maps table columns to semantic categories, each with its own set of rules, score, and match threshold, which can be adjusted to fine-tune Truelty’s accuracy and align it with your data and desired outcomes. The tool uses a variety of algorithms and heuristics to determine the best possible matches, and fuzzy matching can be used judiciously to improve the accuracy of the matching process.
Truelty’s approach to pair matching by semantic category allows for a more robust and accurate identification of possible pathways and matched records, even in cases where data quality is poor or where there are variations in how data is entered. By carving up the data into specific semantic categories and performing pair matching based on these categories, Truelty can identify all possible pathways that may lead to a match, ensuring a high degree of accuracy in identifying duplicate records.
Overall, Truelty’s semantic categories and pair matching process are highly effective in identifying duplicate records and reducing errors, improving data consistency and accuracy.
Understanding Semantic Category Rank Scoring for Improved Data Matching
This guide provides an overview of semantic categories and their use in Truelty, an identity resolution tool built on the Snowflake engine. Semantic categories classify data based on its meaning and context, grouping similar data elements or entities together based on their semantics. Common semantic categories include name, address, phone, email, and more.
Each semantic category is assigned a rank score based on its matching ability, which prioritizes matching and improves the accuracy of identifying duplicate records. The rank score reflects how well a semantic category can be used for matching, with higher scores indicating better matching ability. For instance, a US Passport identifier would be considered an exact matching value and receive a rank score of 10. In contrast, a semantic category for City has a rank score of 2 because it is a poor indicator for matching a person due to the high likelihood of multiple people from the same city.
Truelty comes with a set of predefined core semantic categories, but you can create custom semantic categories to meet your specific needs. For example, you might add a Loyalty Program ID or a Customer ID category.
In Truelty, you map your table columns to semantic categories, each with its own set of rules, score, and match threshold. These can be adjusted to fine-tune Truelty’s accuracy and align it with your data and desired outcomes.
Understanding Semantic Categories Rank Score
Categories ranked as Exact have a score of 10 and a high degree of accuracy. Examples of Exact categories include:
- IMEI
- US SSN
- US Passport
- US Drivers License
Categories ranked as Excellent have a score of 5 and a strong ability to match. Examples of Excellent categories include:
- LAT_LONG
- IBAN
- US Bank Account
- VIN
- US Street Address
- Phone Number
- Payment Card
Categories ranked as Good have a score of 3 and a moderate ability to match. Examples of Good categories include:
- Name
- URL
- IP Address
- Longitude
- Latitude
Categories ranked as Fair or Poor have a score of 2 or 1 and a lower ability to match. Examples of Fair or Poor categories include:
- US City
- US Postal Code
- Date of Birth
- Gender
- Ethnicity
- Marital Status
- Occupation
- US County
- US State or Territory
- Year of Birth
- Salary
- Country
- Age
By default, Truelty excludes low-scoring semantic categories from the matching process since they provide little or zero value or even negative value in some cases. By using semantic categories and ranking them according to their matching ability, Truelty can help organizations identify duplicate records with a higher level of accuracy, reducing errors and improving data consistency.
Section 1: Basics of Semantic Category Matching
In this section, we will cover the basics of semantic category matching, which is a key component of Truelty’s identity resolution process.
Key Terminology
Before diving into the details, let’s cover some key terminology that we will be using throughout this documentation:
- Semantic Category: A logical grouping of data based on its meaning or purpose.
- Pair Match: The process of comparing two sets of data and determining if they are a match.
- Fuzzy Match: A match that is not an exact match, but is similar enough to be considered a possible match.
- Hyper-packing: The process of optimizing the storage and retrieval of data in a database by packing related data together.
The Process
The process of semantic category matching in Truelty can be broken down into the following steps:
- Mapping Columns to Semantic Categories: Each column in a table is mapped to a specific semantic category based on its content.
- Carving Up Data by Semantic Category: The data in each column is stripped and stacked into its corresponding semantic category.
- Pair Matching by Semantic Category: The data in each semantic category is pair-matched against the data in every other semantic category to identify potential pathways for matching records.
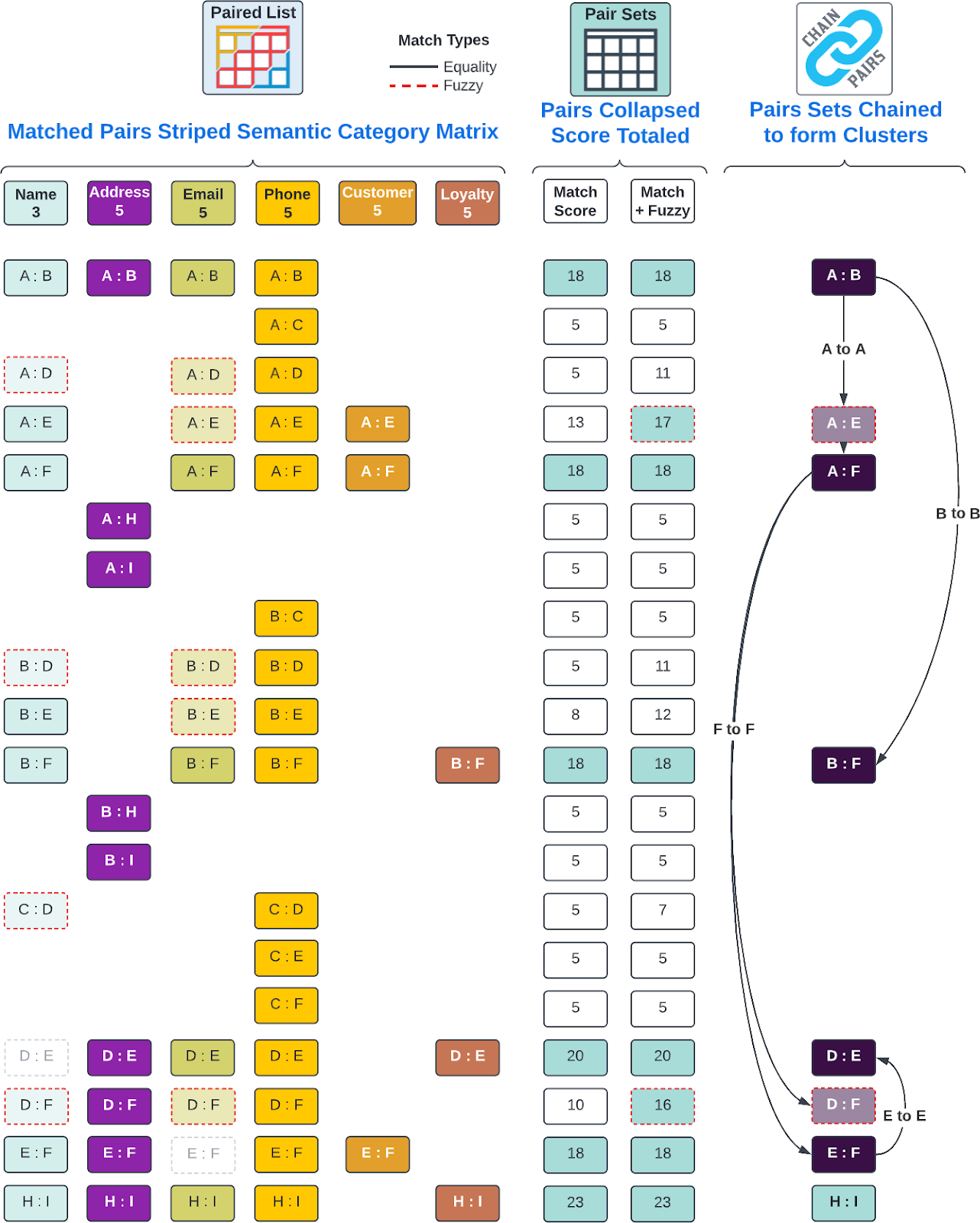
- Summing Match Pairs into Matched Pathways and Scoring the Pathway: All of the pair matches are scored based on their strength of match, and the pair matches with a score of 15 or higher are considered a matched record.
- Chaining Pathways into Matched Records: The pathways that result in a matched record are chained together to form the final matched record.
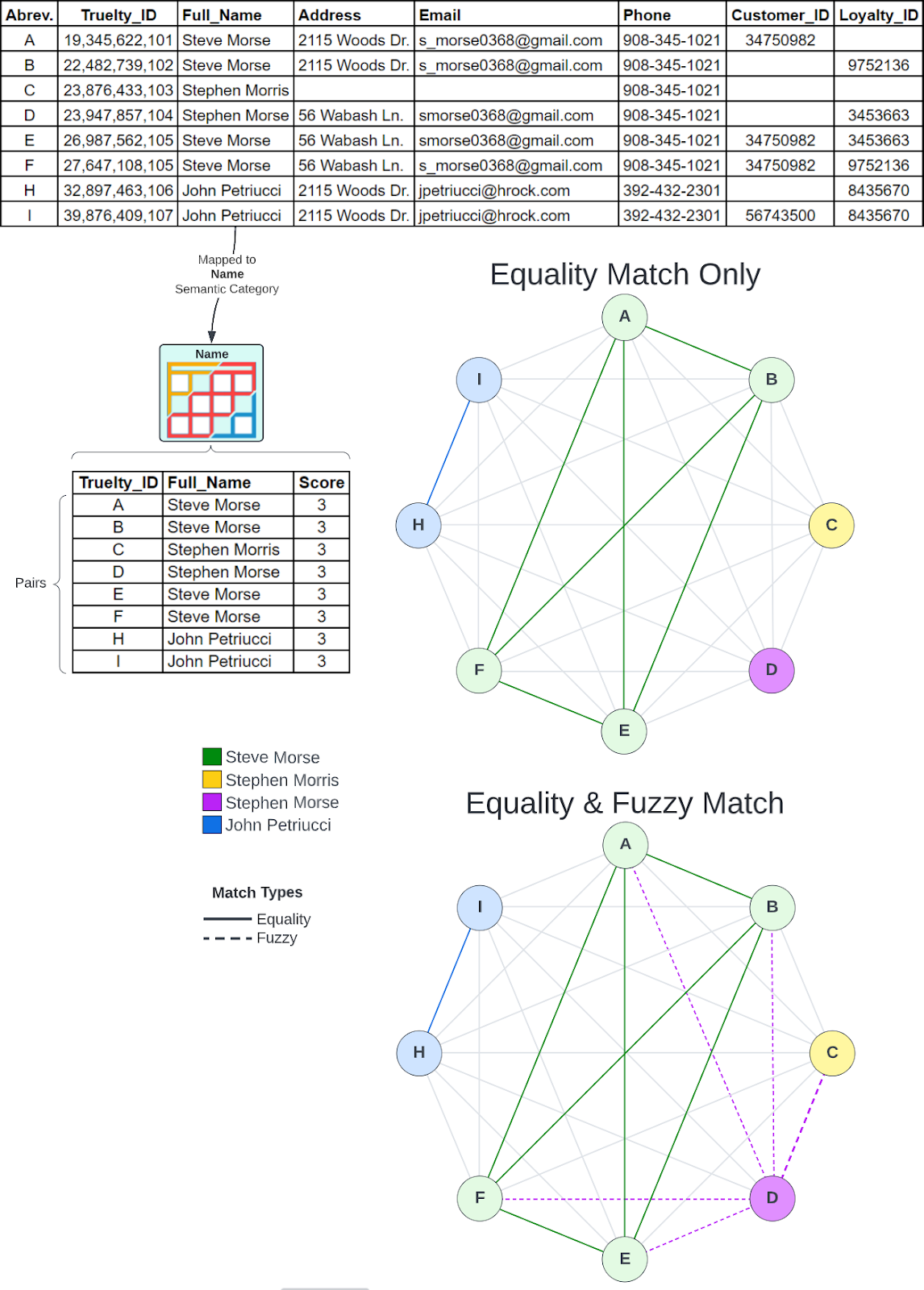
Example Diagram
Here is an example diagram that illustrates the process of semantic category matching in Truelty:
As you can see from the diagram, the process of semantic category matching involves breaking down a row of data into its individual semantic categories and using those categories to identify potential pathways between rows. By taking advantage of high processing capacity in Snowflake, we are able to efficiently compare data and identify matching records.
Section 2: Stripping and Stacking Data into Semantic Categories
In this section, we will cover the process of stripping and stacking data into semantic categories, which is a critical step in Truelty’s identity resolution process.
The Process
The process of stripping and stacking data into semantic categories in Truelty can be broken down into the following steps:
- Mapping Columns to Semantic Categories: Each column in a table is mapped to a specific semantic category based on its content.
- Carving Up Data by Semantic Category: The data in each column is stripped and stacked into its corresponding semantic category.
Example Diagram
Here is an example diagram that illustrates the process of stripping and stacking data into semantic categories in Truelty:
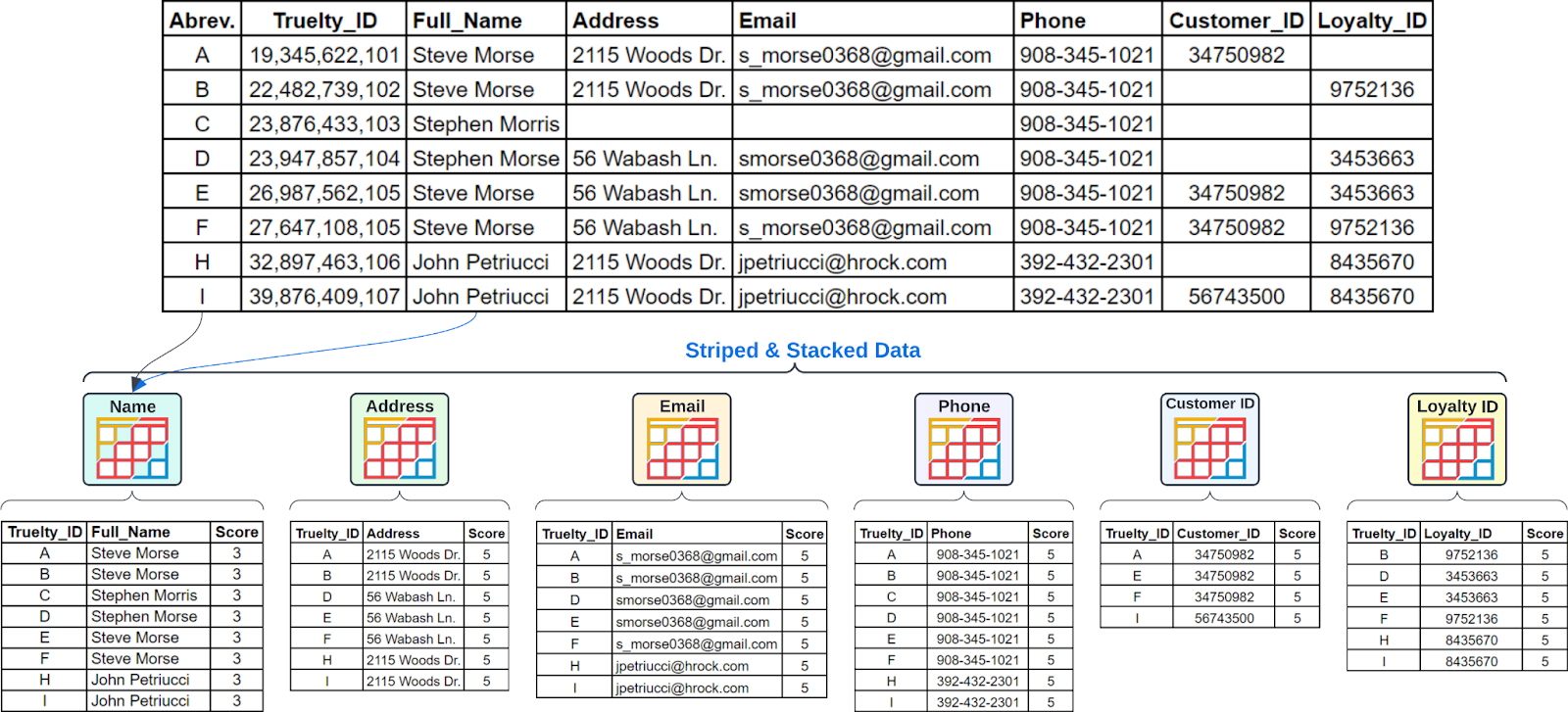
As you can see from the diagram, the data in each column is mapped to a specific semantic category and then carved up and stacked into that category. By doing this, we are able to efficiently compare data and identify matching records.
Section 3: Pair Matching by Semantic Category
Truelty divides the data into discrete datasets, based on semantic categories that are determined during the semantic mapping process. Each dataset contains a unique set of semantic categories, along with their corresponding Truelty ID, value, and score. These datasets are then loaded into Truelty in a hyper-packed format, sorted by value.
Using these datasets, Truelty performs pair matching between the datasets based on their semantic category. For example, if Truelty is comparing the semantic category of “Name”, it will compare all the values of the “Name” category between the two datasets to identify possible matches.
If Truelty identifies a match, it will take the Truelty ID from one dataset and match it with the Truelty ID from the other dataset, creating a pair match. The pair matches are then sorted by their score and added to a list of possible pathways.
The pair matches allow Truelty to identify all possible pathways that may lead to a match, even if there are differences in how the data is entered or if there are missing values. These pathways are then used to identify possible matches and are critical in identifying duplicate records.
It’s worth noting that not all pair matches will result in a matched pathway or a matched record. Truelty uses a variety of algorithms and heuristics to determine the best possible matches, and some pair matches may be deemed not strong enough to be included in the final set of matched records.
Overall, Truelty’s approach to pair matching by semantic category allows for a more robust and accurate identification of possible pathways and matched records, even in cases where data quality is poor or where there are variations in how data is entered.
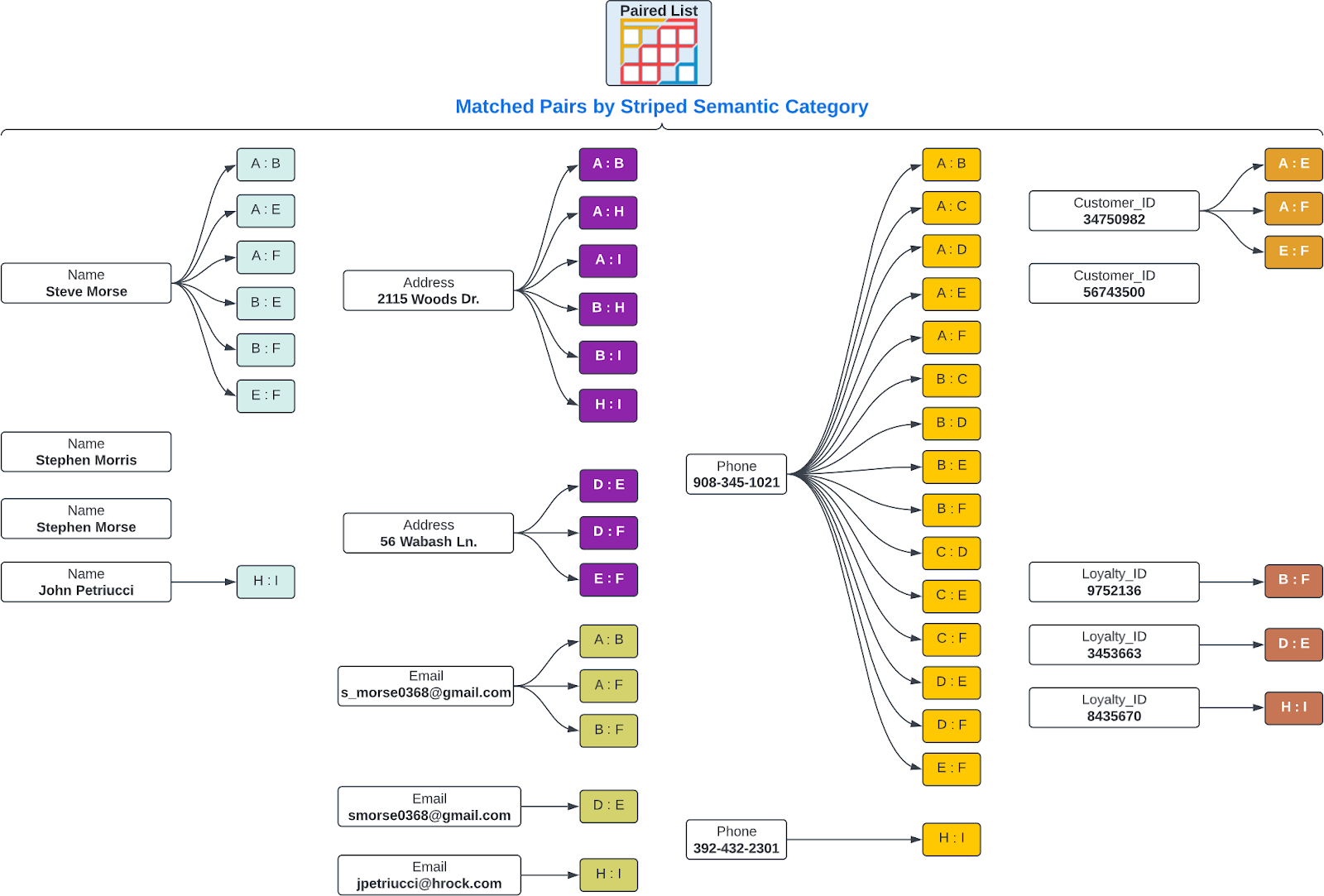
Section 4: Summing Match Pairs into Matched Pathways and Scoring the Pathway and Chaining Pathways into Matched Records
In section 4, Truelty combines the pair matches identified in section 3 into matched pathways. Each matched pathway represents a potential match between two records, based on the similarity of the values in specific semantic categories.
To determine if a matched pathway represents a strong enough match to be considered a matched record, Truelty sums the scores of all the pair matches associated with that pathway. The score for each pair match is determined by its similarity score, which is calculated based on the type of comparison being performed (exact match, fuzzy match, etc.) and the weight assigned to the semantic category.
Truelty has a default threshold value of 15, which represents the minimum score required for a matched pathway to be considered a matched record. If the score of a matched pathway meets or exceeds the threshold value, Truelty considers it a matched record.
Once Truelty has identified all the matched records, it chains together the paired pathways to produce the final set of matched records. During this process, Truelty may identify additional matched records that were not apparent during the pair matching process.
The sum of scores from the pair matches for each pathway is critical in identifying which records are a good match and which records are not. The score indicates the degree of similarity between the records and the higher the score, the greater the likelihood that the records are a match.
It’s important to note that while fuzzy matching can improve the accuracy of Truelty’s matching process, it can also increase the number of false positives. Therefore, it is important to use fuzzy matching judiciously and to set appropriate thresholds to minimize the impact of false positives.
It’s also worth noting that not all paired pathways will result in matched records. Some paired pathways may be discarded during the chaining process, as they do not contribute to producing a final matched record. The final set of matched records is based on the sum of scores and chains of paired pathways.
Overall, Truelty’s pair matching and chaining process is highly effective at identifying matched records, even in cases where data quality is poor or where there are variations in how data is entered. By carving up the data into specific semantic categories and performing pair matching based on these categories, Truelty can identify all possible pathways that may lead to a match, ensuring a high degree of accuracy in identifying duplicate records.