The diagram below is an overview of Truelty’s Snowflake backend processing. The backend processing is orchestrated in Python using the Snowflake Python Connector. The Python app TRUELTY.PY is a CLI that you can run manually or schedule on a recurring basis.
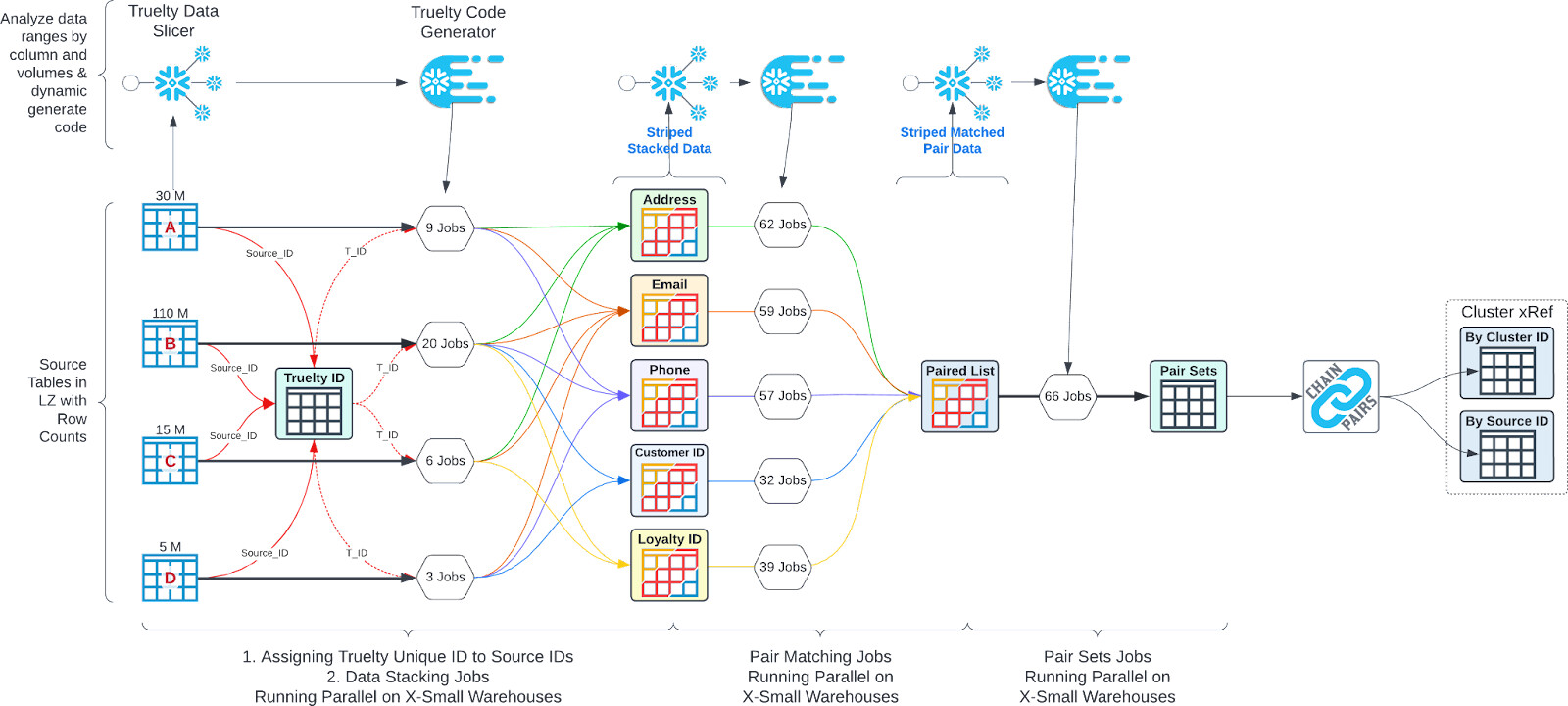
The number of Snowflake SQL jobs will vary based on the volume of data in your source tables and the number of identifiable semantic categories associated with the columns in your tables.
Identifiable semantic categories are data field types used to pair-match and identify a person or entity. Examples of these types of identifiable field categories are:
- IBAN
- IMEI
- IP Address
- Name
- Payment Card
- Phone Number
- URL
- US Bank Account
- US Drivers License
- US Passport
- US SSN
- US Street Address
- VIN
The list above is part of Truelty’s auto-assignment of identifiable semantic categories. As part of the onboarding process, new source tables placed in the TRUELTY.LZ schema are automatically scanned to identify these table columns containing the identifiable data.
Columns that are not automatically identified but contain strong identifiable data, useful to resolve a person or entity, can be added and manually mapped to the columns in the UI. Examples of strong identifiable data are:
- Loyalty Program IDs
- Customer IDs
- Entity IDs
NOTE: Weak or quasi-identifiable data like gender, birthday, and zip codes usually are too general to use when identifying a person or entity.
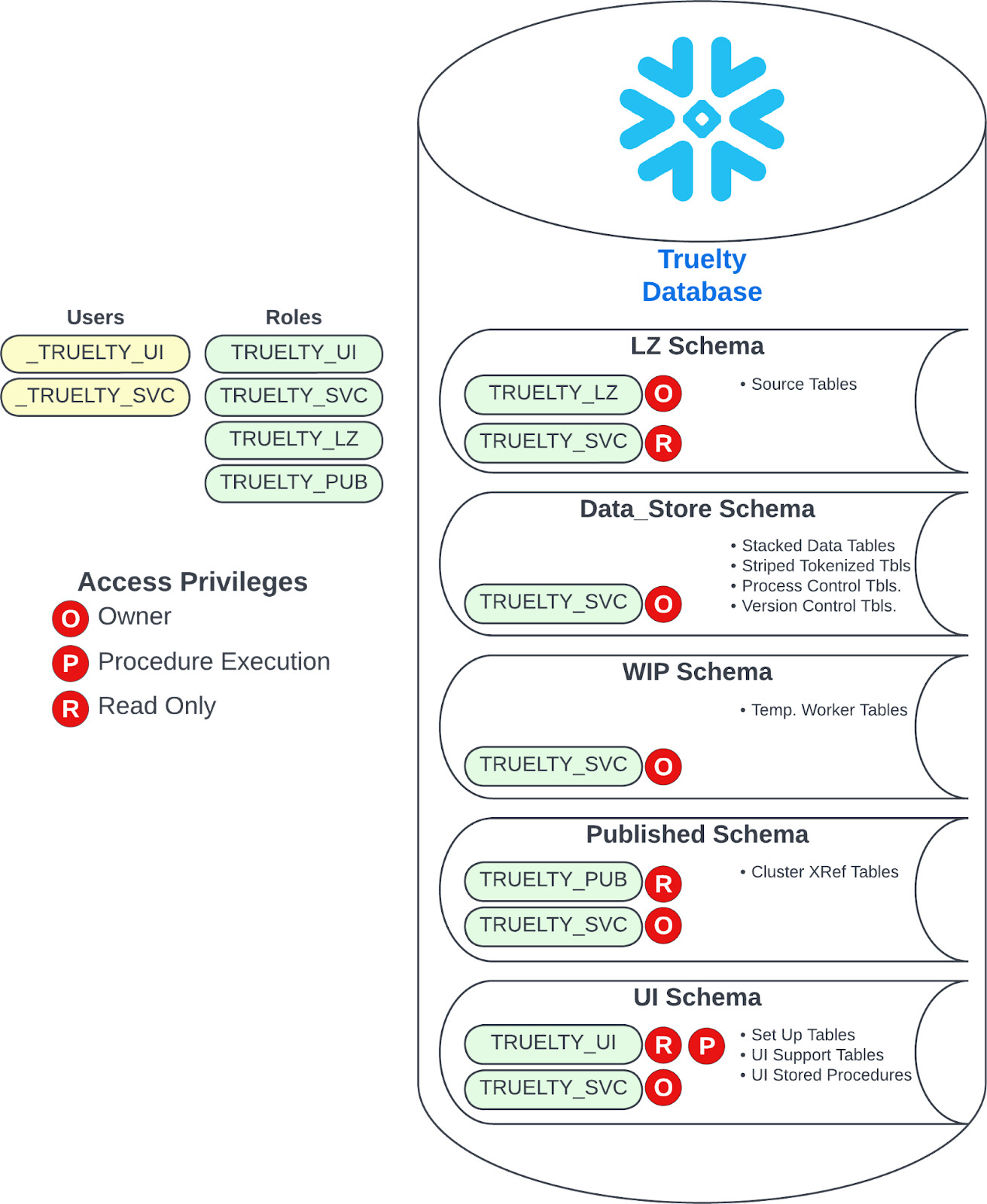
Overview of the Snowflake Objects Created and Grants Applied
Below is a diagram of the Database, Schemas, Users, Roles, and Grants Required to run Truelty that will be created and configured in the Truelty for Snowflake Install.