Introduction
The Truelty Testing Package for Snowflake is designed to make it easy to validate and review processed identity matches from Truelty. This package allows for a wide variety of tests to be performed on the source tables, making it easier to align matches regardless of column naming convention. This user guide outlines the various features of the testing package & how to use it.
Challenge: Working with Multiple Source Tables
Working with multiple tables can be challenging. Different types of columns and naming conventions make it difficult to test matches. Tables from different systems or sources may not have columns of the same name or data type, making it time-consuming to write SQL for testing matches.
Solution: Truelty Testing Package
The Truelty Testing Package for Snowflake addresses these challenges by matching tables based on semantic categories mapped to each table and column. This package makes it easy to validate and review the processed results of Truelty. It provides insights into how common duplications or matches are and saves time by eliminating the need to write complex SQL queries for testing matches.
How it Works
Using a flexible stored procedure in Snowflake using a parameter-based method, you can easily define the test you would like to perform. The testing packages generate the SQL code needed for your request and produces the data for you to compare. Data is aligned based on the semantic category, not the column name. This allows for easy visualization of matching data record by record. Multiples of the same semantic category are grouped together, separated by a pipe for easy comparison. The package shows how many matches each record has to other records across itself and other tables based on the Truelty cluster key.
Overview of the Types of Tests that Can be Performed
The Truelty Testing Package for Snowflake offers various tests that can be performed on source tables:
- Select top N highest duplicate matched records
- Select bottom N least duplicate matched records
- Select N records that are [ = | != | > | < | <= | >= ] X number of matched records in tables listed
- Select Matched records identified by the Truelty cluster_key (one or more keys).
- Select Matched records for unique_source_id [All source tables] (one or more keys)
- Select Matched records for specific Source table(s)
Output Options
The Truelty Testing Package for Snowflake offers two output options:
- Screen (Inside the Snowflake Worksheet or IDE - [default behavior])
- Published to a persistent named table in the truelty.published Schema in Snowflake
How to Run the Package
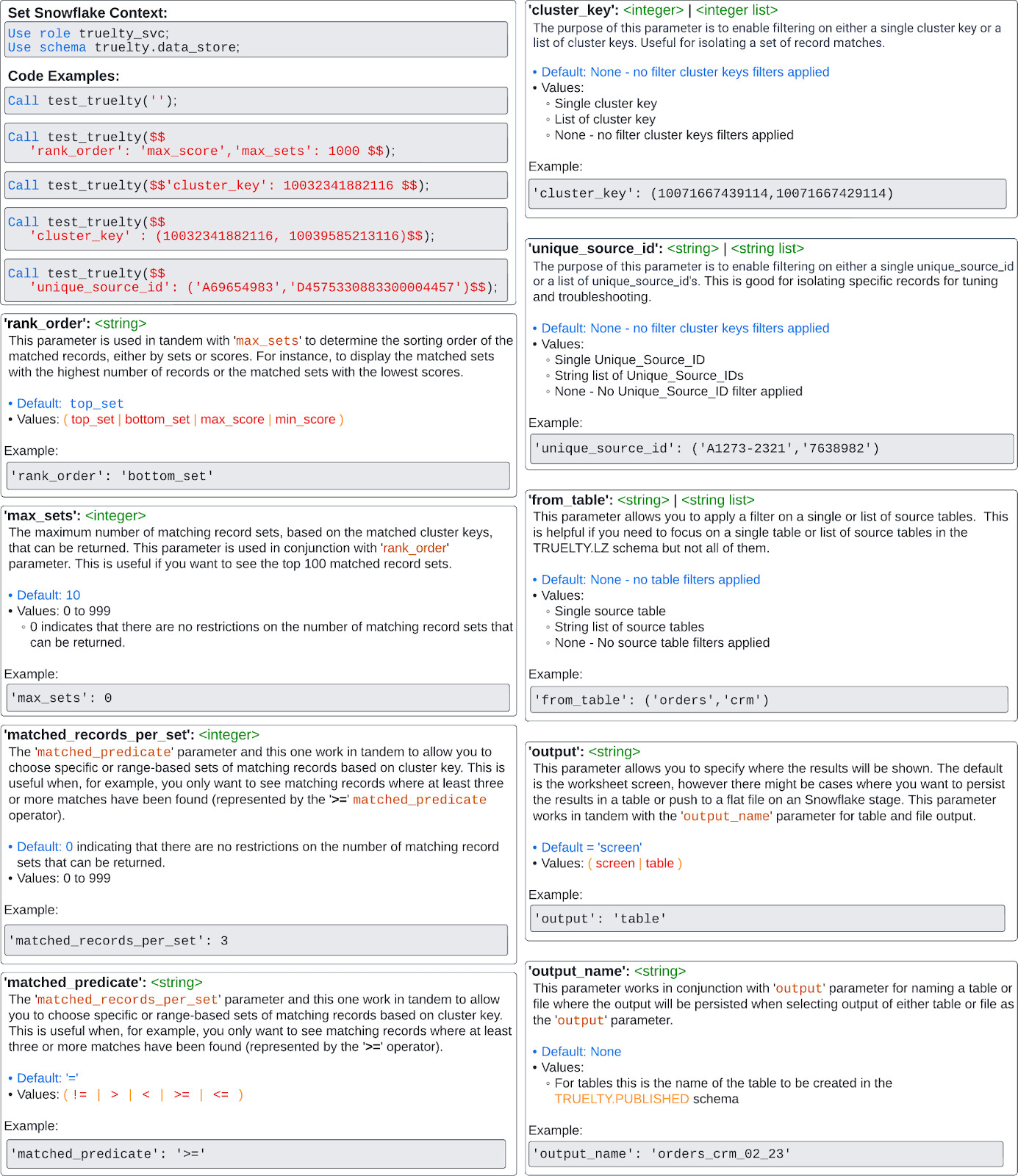
To run the Truelty Testing Package for Snowflake, call it through a stored procedure named ‘**test_truelty(<string>)’ found in the Snowflake truelty.data_store schema. Ensure you are using the role of ‘truelty_svc’ directly or through role inheritance.
Use the following code to set the Snowflake context to make it easy to use and ensure you are using the **truelty_svc role.
Use role truelty_svc;
Use schema truelty.data_store;
The ‘**test_truelty(<string>)’ stored procedure supports the ability of an overload parameter, meaning you can provide any of the parameters in any order that fits your testing use case. Overloading a parameter refers to defining multiple functions or methods with the same name but different parameter types or numbers. When a Snowflake stored procedure is overloaded, it can accept different arguments and perform different operations based on the types or the number of arguments passed to it.
The simplest call is to provide no parameters using the default values. Since the stored procedure expects a string even when providing no parameters, at a minimum, you need to provide a string empty set ‘’.
Example:
Call truelty.data_store.test_truelty('');
Or if you have set your Snowflake context as shown above you can simply use the following:
Call test_truelty('');
This returns the top 10 matched sets ordered by the highest total number of matches per Truelty cluster_key. You can mix and match parameters as needed, including the use of distinct values and lists of values for the parameters that support lists.
Parameter Formatting & Syntax
The formatting of the parameters follows a key-value pair approach.
The parameter name is key and needs to be in quotes, followed by the value. If the value is a string, it needs to be in quotes as well. If the value is an integer, no quotes are needed. When the value is a list, then the list is enclosed by parentheses. If multiple parameters are used, each key-value set is delimited by a comma. Note the parameters are case-sensitive and should all be lowercase.
→ NOTE: The parameters are case-sensitive and should all be lowercase. ←
Important Note: Often, you will be using a combination of quotes and commas, which can confuse SQL. It is recommended to use the double dollar sign delineation ‘$$’ at the beginning and end of the parameter string.
Below are two SQL examples of proper parameter syntax; note the use of ‘$$’ at the beginning and end of the parameter sets.
Example 1:
Call test_truelty($$'rank_order': 'top_set','max_sets': 1000 $$);
Example 2:
Call test_truelty($$
'rank_order': 'top_set',
'max_sets': 100,
'matched_records_per_set': 4,
'matched_predicate' : '>=',
'cluster_key' : (10032341882116, 10039585213116),
'unique_source_id' : ('A69654983', 'D4575330883300004457'),
'from_table' : ('CUSTOMERS_EAST', 'CUSTOMERS_ORDERS')
$$);
Testing Parameter Details
Below is a list of all the possible parameters that can be used with the key value definitions. Each value data type is provided. Many of the parameters have default values which are identified in the description of the parameters. Some parameters allow for an integer value for whether sets, records, etc. In these cases, the value of 0 represents unlimited or ALL. Other parameters have a very specific list of approved values to use. The approved list of values is listed in the description of each parameter. Note: All valid values are lowercase.
‘rank_order’: <string>
This parameter is used in tandem with ‘max_sets’ to determine the sorting order of the matched records, either by sets or scores. For instance, to display the matched sets with the highest number of records or the matched sets with the lowest scores.
Default: ‘top_set’
Values:
- top_set
- bottom_set
- max_score
- min_score
Example syntax:
'rank_order': 'bottom_set'
SQL Code Example:
Call test_truelty($$'rank_order': 'top_set','max_sets': 1000 $$);
‘max_sets’: <integer>
The maximum number of matching record sets, based on the matched cluster_key(s), that can be returned. This parameter is used in conjunction with ‘**rank_order’ parameter. This is useful if you want to see the top 100 matched record sets.
Default: 10
Values: 0 to 9999
- 0 indicates that there are no restrictions on the number of matching record sets that can be returned.
Example syntax:
'max_sets': 0
SQL Code Example:
Call test_truelty($$'max_sets': 1000,'rank_order': 'top_set'$$);
‘matched_records_per_set’: <integer>
The ‘matched_predicate’ parameter and this one work in tandem to allow you to choose specific or range-based sets of matching records based on cluster key. This is useful when, for example, you only want to see matching records where at least three or more matches have been found (represented by the ‘>=’ matched_predicate operator).
Default: 0 Indicating that there are no restrictions on the number of matching record sets that can be returned.
Values: 0 to 9999
Example syntax:
'matched_records_per_set': 3
SQL Code Example:
Call test_truelty($$
'matched_records_per_set': 2,
'matched_predicate' : '>=',
'rank_order': 'top_set',
'max_sets': 0
$$);
## 'matched_predicate': <string>
The 'matched_records_per_set' parameter and this one work in tandem to allow you to choose specific or range-based sets of matching records based on cluster key. This is useful when, for example, you only want to see matching records where at least three or more matches have been found (represented by the '**<code>>=</code></strong>' operator).
Default: '='
Values: != | > | < | >= | <=
Example syntax:
‘matched_predicate’: ‘>=’
SQL Code Example:
Call test_truelty($$
‘matched_predicate’ : ‘>’,
‘matched_records_per_set’: 6,
‘rank_order’: ‘top_set’,
‘max_sets’: 100
$$);
## 'cluster_key': <integer> | <integer list>
The purpose of this parameter is to enable filtering on either a single Truelty **<code><em>cluster_key</em></code></strong> or a list of <strong><code><em>cluster_key's</em></code></strong>. Useful for isolating a set of record matches.
Default: None - No cluster_key(s) filters applied
Values:
* Single cluster_key
* List of cluster_keys
* None - No cluster_key(s) filters applied
Example syntax:
‘cluster_key’: (10071667439114, 10071667429114)
SQL Code Example 1:
Call test_truelty($$‘cluster_key’: (10032341882116,10039585213116)$$);
SQL Code Example 2:
Call test_truelty($$‘cluster_key’ : 10032341882116 $$);
## 'unique_source_id': <string> | <string list>
The purpose of this parameter is to enable filtering on either a single **<code><em>unique_source_id</em></code></strong> or a list of <strong><code><em>unique_source_id's</em></code></strong>. This is good for isolating specific records for tuning and troubleshooting.
Default: None - No unique_source_id filters applied
Values:
* Single unique_source_id
* String list of unique_source_id’s
* None - No unique_source_id filter applied
Example syntax:
‘unique_source_id’: (‘A1273-2321’,‘7638982’)
SQL Code Example 1:
Call test_truelty($$‘unique_source_id’: (‘A1273-2321’,‘7638982’)$$);
SQL Code Example 2:
Call test_truelty($$‘unique_source_id’: ‘A1273-2321’$$);
## 'from_table': <string> | <string list>
This parameter allows you to apply a filter on a single or list of source tables. This is helpful if you need to focus on a single table or list of source tables in the _TRUELTY.LZ_ Snowflake schema but not all of them.
Default: None - no table filters applied
Values:
* Single source table
* String list of source tables
* None - No source table filters applied
Example syntax:
‘from_table’: (‘orders’,‘crm’)
SQL Code Example 1:
Call test_truelty($$‘from_table’: (‘orders’,‘crm’), ‘max_sets’: 100 $$);
SQL Code Example 2:
Call test_truelty($$‘from_table’: ‘orders’, ‘max_sets’: 100 $$);
‘output’: <string>
This parameter allows you to specify where the results will be shown. The default is the worksheet screen. However, there might be cases where you want to persist the results in a table in Snowflake. This parameter works in tandem with the ‘output_name’ parameter for table output.
Default: ‘screen’
Values:
- screen
- table
Example syntax:
'output': 'table’
SQL Code Example:
Call test_truelty($$
'output': 'table',
'output_name': 'orders_crm_02_23',
'max_sets': 0 $$);
‘output_name’: <string>
This parameter works in conjunction with ‘**output’ parameter for naming a table or file where the output will be persisted when selecting output of the table as the ‘output’ parameter.
Default: None
Values:
- For persisting the result to a Snowflake table, this is the name of the table to be created in the TRUELTY.PUBLISHED schema in Snowflake
Example syntax:
'output_name': 'orders_crm_02_23'
SQL Code Example:
Call test_truelty($$
'output_name': 'orders_crm_02_23',
'output': 'table',
'max_sets': 0 $$);
Truelty Testing Package Cheatsheet